API Documentation
7.5
This is a summary of what APIs we have in Preservica 7.5. If you've been using Preservica for a while and just want to know what changed, you can look in the "recent changes" blog posts on our developer blog. This resource can act as a high level reference for all of our APIs.
Each API section on this page is expandable to give you a summary of that API. The two APIs you're mostly likely to need first are the Access Token API and Entity API.
Several of our APIs are marked as Versioned. For more information about that, see this post describing how we do API versioning.
Most of our APIs return JSON from most endpoints, but check the docs for the individual endpoint as some don't.
Please note: access to some APIs may be restricted or subject to a transaction limit, based on your current Preservica edition.
Before you use any of our other APIs, you'll need to get an access token through this one.
In most cases that will mean submitting your user name and password to the /login endpoint. It's also a good idea to send the tenant – if you don't know what your tenant name is, log in once without it but requesting the user details, which includes it. These parameters must be passed in the post body and the format must be x-www-form-urlencoded:
[email protected]&password=xyz&tenant=INST
The response to this (assuming your credentials are valid) will give you a JSON response containing an access token:
{
"success": true,
"token": "0629571d-072b-4fce-bbeb-dc83e9a8ad0c",
"refresh-token": "08437ed2-4bd1-489a-8d20-463544b05437",
"validFor": 15,
"user": "[email protected]"
}
You can then use the access token (in the token field) to authenticate with our other APIs, by setting the Preservica-Access-Token custom header, or a Bearer type Authorization header.
If you include the optional parameter &includeUserDetails=true then you will receive additional information including the tenant and roles, which can be useful for building a user facing application:
{
"success": true,
"token": "215211d4-ab86-44aa-b355-5f02433d2018",
"refresh-token": "31eed469-f95b-4930-af55-d3c6e7ccb31b",
"validFor": 15,
"user": "[email protected]",
"fullName": "Joe Bloggs",
"email": "[email protected]",
"tenant": "INST",
"tenantValue": "686ef128f436af3d9354d18a7aaec0aa"
"roles": [
"ROLE_SDB_MANAGER_USER",
"ROLE_SDB_REGISTRY_ADMIN_USER"
],
"lastSuccessfulLogin": "2021-04-26T11:07:47.000+01:00"
}
If you're already logged in you can also get this information from /api/user/details.
Token Lifetime and Refresh
Newly created access tokens last for 15 minutes (this is the validFor field in the response). Before that token expires, you will need to generate a new one. You could just request a new token with credentials each time, but in a user facing scenario this means you need to request the password each time. Instead, it's better to use the refresh token with the /refresh endpoint.
Submit the current access token as the authentication, and the refresh token in the refreshToken parameter. You will receive a response similar to what you get from /login, with a new access token and new refresh token.
Note that unlike OAuth 2, you can't use a refresh token after the initial access token expires, so you can't wait for a 401 and then refresh, or have 'remember me' like functionality where you store a refresh token. You must proactively manage your token refreshes.
Cookie Based Authentication
If you are using the APIs in a context where cookies are supported, for example in a user facing browser application or using libraries that support cookies, you can request that our API saves a cookie with your access token. This cookie won't be accessible to script, making it harder to hijack or steal with a XSS attack on your site. To use the APIs in this way:
- Make your login request passing cookie=true. If you're using the /login (or temporary users, see the Admin API) endpoint, this also needs to be in the POST body.
- When you need to refresh your token, you can call /refresh with cookie=true, and no refresh token. Your access token cookie will be refreshed if necessary. This will keep your session alive, so you are responsible for ensuring your session management aligns with appropriate security policies around session timeouts.
Your script doesn't need to know about the access token at all.
Two Factor Authentication
If 2FA is enabled on a tenant, your API logins will have to perform 2FA as well. (Accounts which only have the Anonymous role are an exception, so you can serve a public anonymous portal like our UA/Portal with API logins.) If you want to use a service account for automated scripting, you should keep the credentials and the token generating key separate, otherwise you don't really have two factors! For a user facing application you should prompt the user for the second factor.
In terms of the mechanics of authenticating with 2FA:
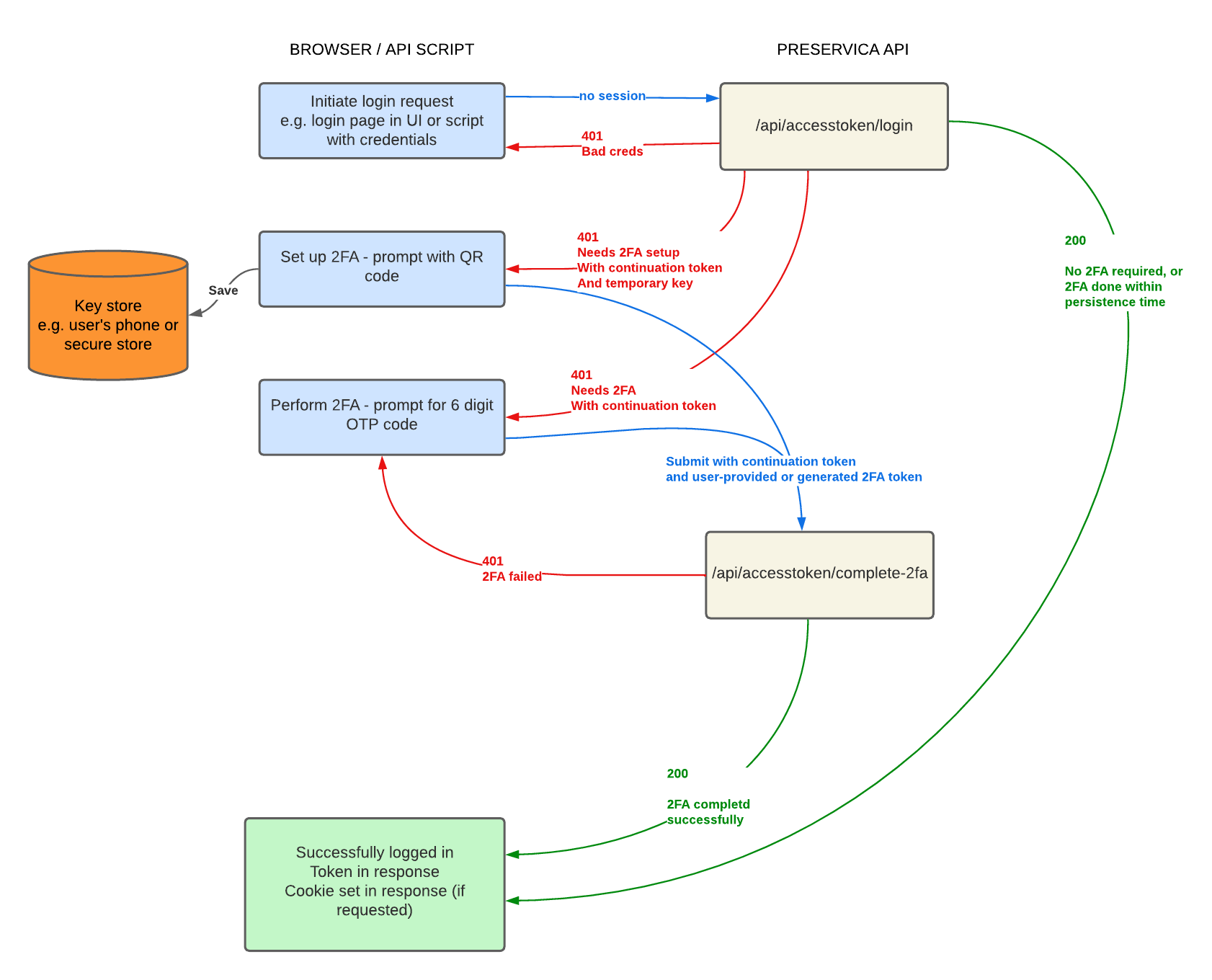
- The request to /login (or other initial login endpoints) will return a HTTP 401 (because your authentication is not complete), the message will contain "needs.2fa", and the value will include a continuation-token.
- You should prompt the user (or generate, for a non-interactive service) the 2FA six digit token and submit it to complete-2fa endpoint. Our 2FA follows RFC4226/6328 for time based one time passwords (the same as Google Authenticator etc). Because it's time based, if you're generating a token, make sure the clock on the system is accurate.
- If you receive "needs.2fa.setup" rather than "needs.2fa", the response will also contain a secretKey. This is the authenticator key which you should save, or show to the user in a way that they can save (e.g. we use it to show a QR code that an authenticator app can save). As above, you need to generate or prompt for a valid authenticator code using this key and make a call to complete-2fa. Once you successfully call complete-2fa, the authenticator key will be saved against that user and future login requests will require it.
- The response from complete-2fa is the same as you get from login if 2FA is disabled, containing an access token that you can use as normal.
- You will also get a cookie (Preservica_2FA_{user-hash}) set. You can pass this to future /login requests to skip 2FA if you already did it within the persistence time. This is most useful if you are using the API to back a user facing application. You can safely send all these cookies with different hashes to the API, only the one for the right user will be inspected.
- Failures: If a user enters an incorrect code too many (3) times, their account will be locked and a manager will need to unlock them from the 2FA configuration page. The number of failures and maximum attempts will be returned in the failure response.
There are more details in this blog post by Andy from our CX team.
Logging Out
Your access token will expire after 15 minutes if you don't refresh it. For many use cases, this is good enough. But if you want to force a session to close, you can call close-current, or revoke.
External Authentication
If you want to support SAML in a user facing portal, don't use this API to do it – instead, you should forward your users to /auth/login (or /auth/login/{tenant-value}) and allow our auth service to manage the SAML interaction. A successful authentication loop there will set the access-token cookie which can be used to authenticate with our APIs.
You can use acquire-external to assert a user identity when you don't have credentials, for example if you are managing an external authentication integration that Preservica doesn't support. You need to share a secret between Preservica (in system properties) and your integration, and it is extremely important to keep this secret secure as it enables logging in as any user on your tenant.